
Meta’s Downloaded 81TB from Shadow Libraries for AI Training, Court Documents Revealed
Published on February 7, 2025

- Freshly unsealed court files documented that Meta torrented over 81TB of data via Anna’s Archive.
- Internal emails even revealed Meta employees faced limited availability of seeders and slow download speeds.
- Employees avoided torrenting via Facebook infrastructure to eliminate traceability to Meta servers.
Meta's use of shadow libraries as a data source for training its artificial intelligence (AI) models was documented in freshly unsealed court files. Despite prior knowledge of Meta's use of the BitTorrent protocol, these revelations showcase the vast scale of data Meta allegedly downloaded.
According to the unsealed documents, Meta sourced data from shadow libraries such as Anna’s Archive, the Z-Library platform, and LibGen. Internal communications from Meta employees also reference the use of the Internet Archive, though it falls outside the typical shadow library framework.
“Just last spring, Meta torrented at least 81.7 terabytes of data across multiple shadow libraries through the site Anna’s Archive, including at least 35.7 terabytes of data from Z-Library and LibGen.” says the court document.
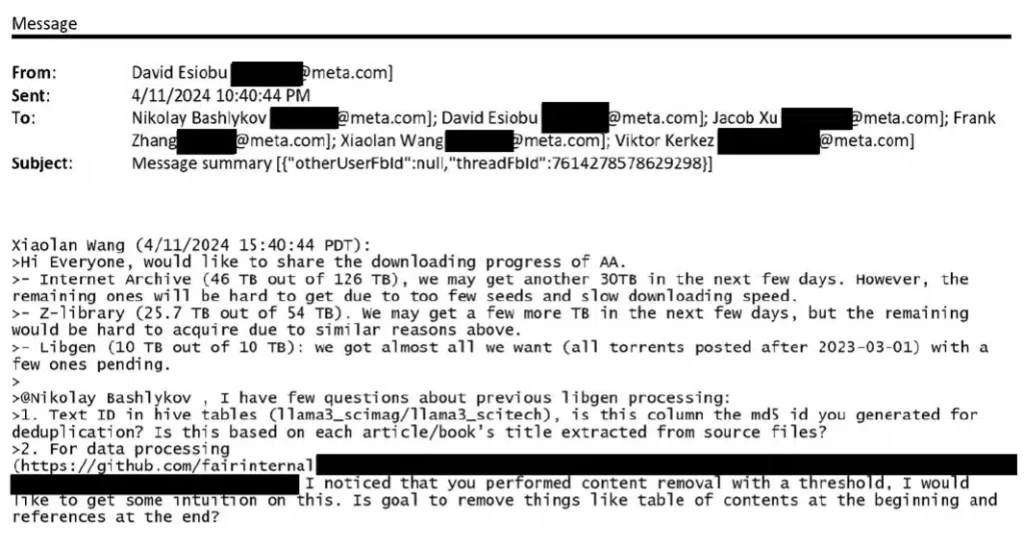
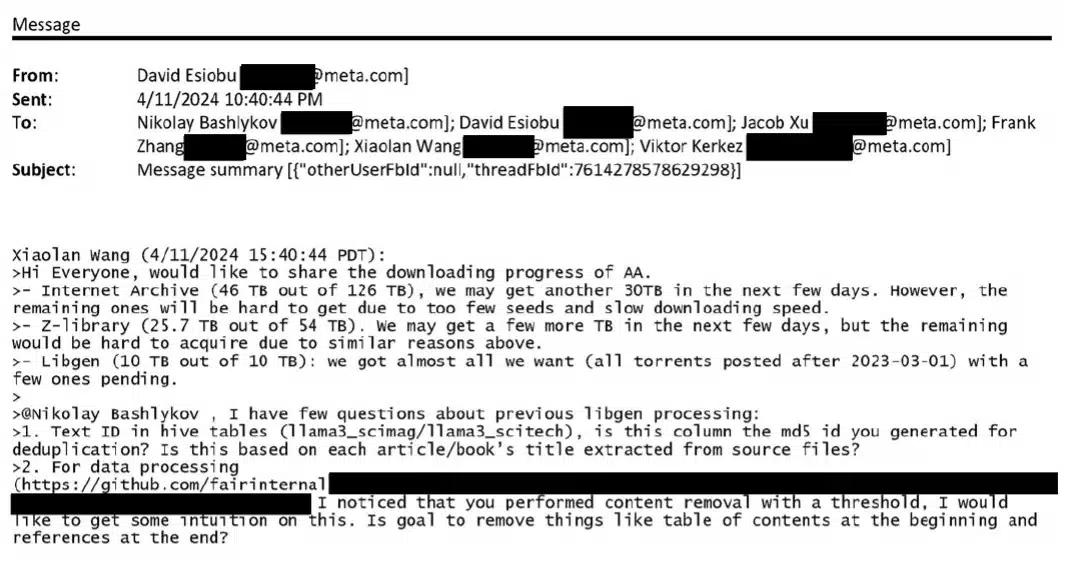
The internal emails reveal challenges during this process, including limited availability of seeders and slow download speeds. These issues stalled data acquisition but did not deter Meta from downloading significant amounts of data using BitTorrent technology. Notably, Meta employees referred to Anna's Archive in internal discussions using initials like "AA."
Meta's employees expressed ethical reservations about using pirated materials. Staff also discussed avoiding Facebook infrastructure for torrenting activities due to concerns over traceability to Meta servers.
While acknowledging the complexities of accessing shadow library data, Meta's internal communications also recognized the potential legal risks. Using the BitTorrent protocol, for example, was deemed "legally problematic" as it potentially facilitated further copyright infringement.
The use of shadow libraries has led to significant legal challenges for Meta. A class-action lawsuit was filed by authors including Richard Kadrey, Sarah Silverman, and Christopher Golden, accusing Meta of copyright infringement.
As part of the legal discovery process, plaintiffs sought access to Meta's torrent client logs and seeding data—requests that Meta successfully denied in court. Nonetheless, plaintiffs obtained substantial evidence during the discovery process, including internal emails that now form part of public court records.
Meta is not alone in leveraging shadow libraries; other companies, like Chinese AI leader DeepSeek, used pirated data to train AI models.
Related





Most Popular




Most Popular